



Not the Shortest Path – Convert a Directory of Satellite Images to a Cloud Optimized Geotiff (COG)



Not The Shortest Path – Ep. 0 🌎 📡 💾
What is ‘Not the Shortest Path’?
I really enjoy writing and sharing some of my ideas or work, but I have been struggling to create a consistent habit out of it. I find it difficult to let go of what others might think. I am committing to letting go of my fears of judgment. I am not a writer, nor just a developer.
I will be sharing anything interesting that I’ve experimented with in Geospatial without skipping the errors along the way. It won’t be perfect, but it will be truthful. We, developers, consistently simplify the stories of how we got to an expected result. There is a tone of learning that happens outside of the linear path from point A to B. I hope that sharing some of my trials and errors will interest a few or at least serve as documentation for my future self.
The Problem
For a project on land-use change and reforestation in the greater Montreal area, we were given access to 25cm aerial imagery. The imagery came in a separate folder with thousands of images.
- Create a single unified Cloud Optimized Geotiff (COG)
- Use a mosaic approach
There is also the virtual (.vrt) approach, but it is not really performant enough to be considered.
The mosaic approach is interesting because a single endpoint can be used to serve all the separate images. The mosaic.json file used by the endpoint is used as a sort of index where the reference to each image is known for every quad key. When additional images need to be added or existing images need to be modified, we simply have to update the mosaic file to match those changes.
I would’ve loved to use the mosaic approach, but I ran into errors on a previous project trying to implement the solution with high-resolution imagery where each image had a small extent. The one-line explanation I would give is that there is an index problem that happens with quad keys and high-resolution imagery when working at low zoom levels and images with small extents. The issue with TiTiler is further documented in 287, 290, and 291.

We are left with the alternative of creating a unified COG. Given that no modifications will be applied to the raw imagery at a later date, we won’t have to regularly re-compute the COG. The requirements of the COGs we usually use for our current applications are the following:
- Projected in EPSG:3857
- Single merged file
- Added overviews(its a COG after all)
- No distortions or artifacts
First Attempt — Project, Merge, and Overviews
In the first attempt, I used the logic of projecting all the raw imagery into the desired EPSG:3857, merging the output of the projection, and finally adding the overviews to the merged file. The series of GDAL commands I used are shown in the code:
#!/bin/bash
directory=raw_images_folder
image_extension=tif
destination=projected_path
# project
for FILE in "$directory/"*."$image_extension"; do
echo $FILE
[[ -e "$FILE" ]] || break
local file_name="${FILE##*/}"
gdalwarp -t_srs "EPSG:$projection_epsg_code" "$FILE" "$destination/$file_name"
done
# merge
tmp_vrt=tmp.vrt
merge_file=merge_path.tif
gdalbuildvrt "$tmp_vrt" "$destination/"*."$image_extension"
gdal_translate -of GTiff -co "COMPRESS=DEFLATE" -co "BIGTIFF=YES" "$tmp_vrt" "$merge_file"
# add overviews
gdaladdo "$merge_file" 2 4 6 8 16 32 64 --config COMPRESS_OVERVIEW DEFLATEIn the first attempt, I used the logic of projecting all the raw imagery into the desired EPSG:3857, merging the output of the projection, and finally adding the overviews to the merged file. The series of GDAL commands I used are shown in the code:
The fault in this might be apparent to anyone with sufficient experience with image processing, but it did not hit me until seeing the final output:
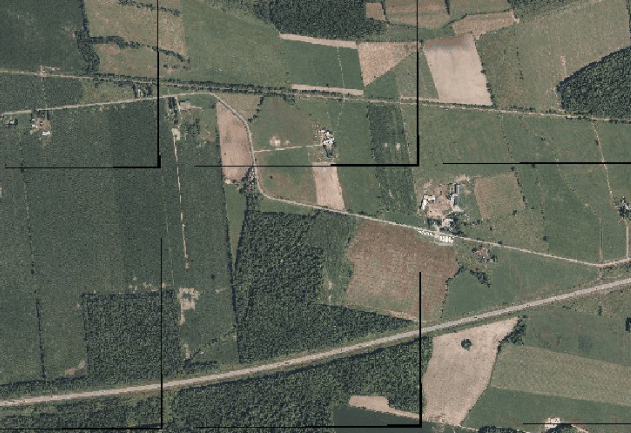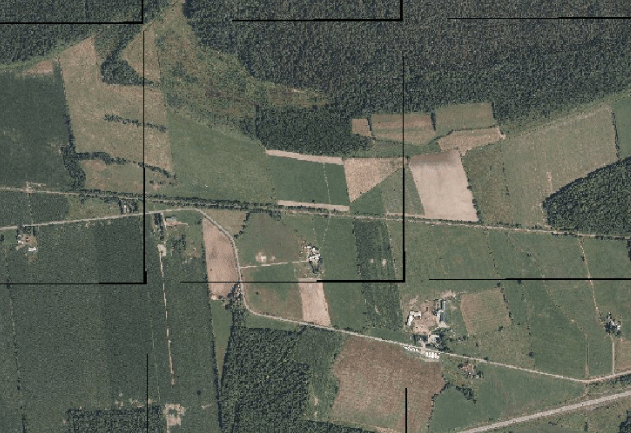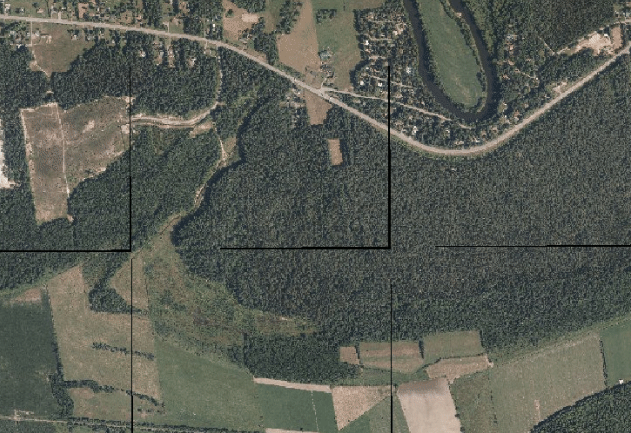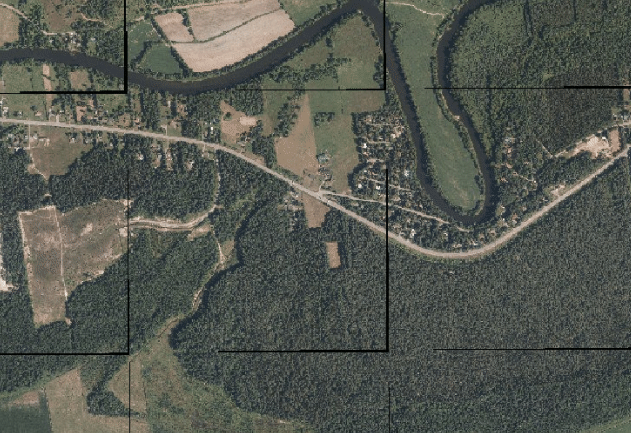
The gdalwarp commands were filling in null values along the border of each individual image. When merging the images, it simply sows the projected images with their null values together. The final COG contains the same artifacts.
Another error I made was not optimizing the initial GDAL calls for performance which took the time to process the images on my machine excessively long. The final output COG weighs over 200G and took approximately a day to compute.
Second and Final Attempt — Merge, Project, and Overviews
We were rather convinced that the artifacts were the result of executing the projection before the merge. Our hypothesis was to switch the faulty merge and the projection step.
I also took the time to look into how to optimize calls to gdalwarp and gdal_transform . The general idea is to add configuration parameters to increase the number of CPUs, increase the cache size available, and verify the compression and tiling settings to reduce the memory required. The processing time was reduced from a day to ~2 hours.
#!/bin/bash
gdalbuildvrt tmp.vrt data/raw/2019_aout/25cm/*.tif
gdal_translate -of GTiff --config GDAL_CACHE_MAX 80% -co TILED=YES -co BIGTIFF=YES -co COMPRESS=DEFLATE -co NUM_THREADS=ALL_CPUS tmp.vrt 2019_aout_25cm_merge.tif
gdalwarp -of GTiff -multi -wm 80% -co TILED=YES -co BIGTIFF=YES -co COMPRESS=DEFLATE -co NUM_THREADS=ALL_CPUS -t_srs "EPSG:3857" 2019_aout_25cm_merge.tif 2019_aout_25cm_3857.tif
gdaladdo 2019_aout_25cm_3857.tif 2 4 6 8 16 32 64 --config COMPRESS_OVERVIEW DEFLATE -co NUM_THREADS=ALL_CPUS
Conclusion
One of my key takeaways is no matter how powerful the tool you use to process imagery or other data for that matter, we can’t hide all of the intricacies to the end-user. GDAL is a tremendously flexible and great tool, but it is up to us end-users to figure out how to use it in a given context.
I also learned that starting with subsets of your data is key to experimenting and getting rapid feedback on your data pipelines. However, there is a subset of issues that only arise when working at scale. Reading on best practices before launching a process on 150G of data is time well invested.
I hope that sharing more developer stories in a more curated way than StackOverflow will make these intricacies more accessible.